图形绘制概述
Android框架提供了两种绘制图形的方式:Canvas和OpenGL.
android.graphics.Canvas是一个2D图形API, 并且是在开发者中最流行的图形API. Canvas运算会在Android中绘制所有原生和自定义android.view.View. 在Android中,Canvas API通过一个名为OpenGLRender的绘制库实现硬件加速,该绘制库将Canvas运算转换为OpenGL运算,以便它们可以在GPU上执行。
从Android 4.0开始,硬件加速的Canvas默认情况下处于启用状态。因此,支持OpenGL ES 2.0的硬件GPU对于Android 4.0及更高版本的设备来说是强制要求。
除了Canvas,开发者渲染图形的另一个主要方式是使用OpenGL ES直接渲染到Surface. Android在Android.opengl包中提供了OpenGL ES接口,开发者可以使用这些接口通过SDK或Android NDK中提供的原生API调用其GL实现。
Android图形组件
无论开发者使用什么渲染API,一切内容都会渲染到”Surface”. Surface表示缓冲队列中的生产方,而缓冲队列通常会被SurfaceFlinger消耗。在Android平台上创建的每个窗口都由Surface提供支持。所有被渲染的可见Surface都被SurfaceFlinger合成到显示部分。
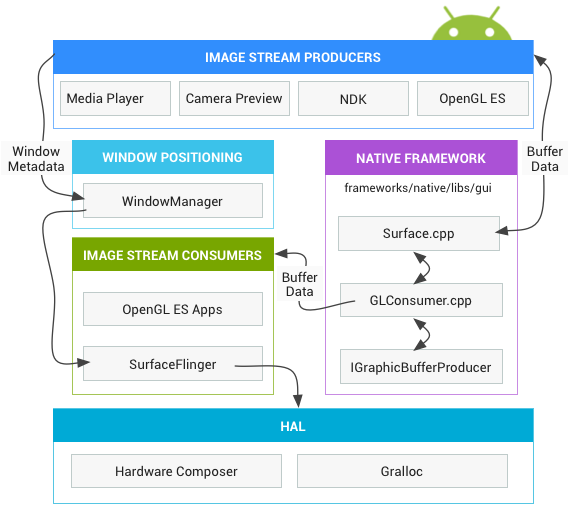
所以,在App进程与WMS的通信过程中,我们会重点关注Surface的创建过程。
比喻
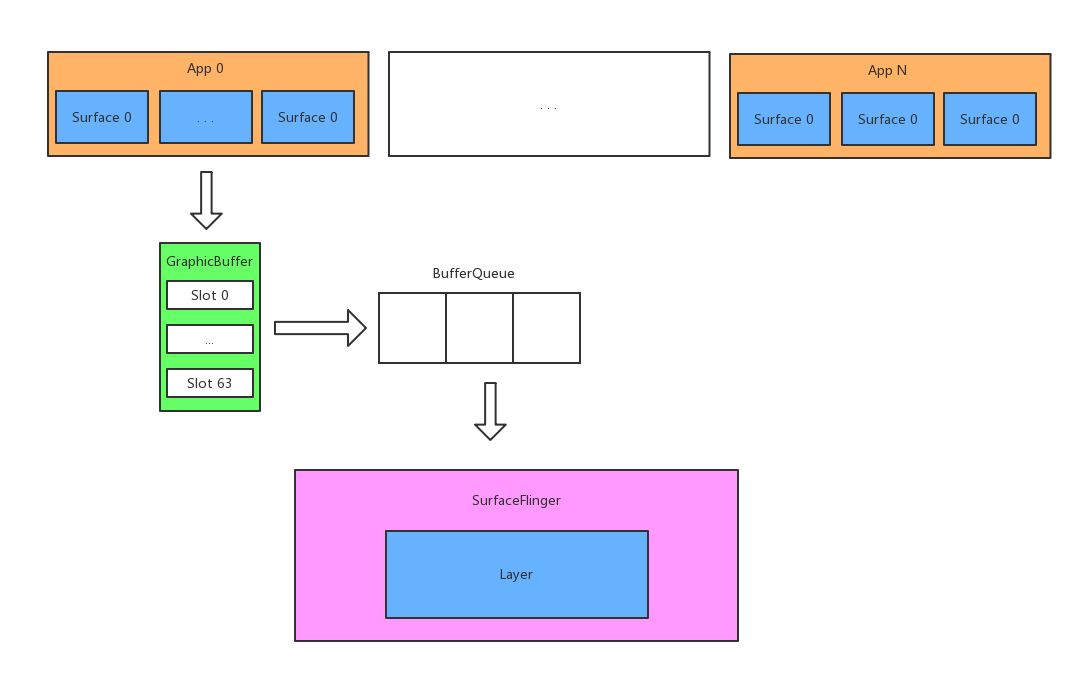
- 就像我们画画需要画板一样,App绘制图形也需要,在Android中这个画板就是”Surface”,App进程中每个窗口在Java层和C++层各有一个Surface
- Linux中有一个FrameBuffer(帧缓冲区),系统会定时地从其中取出数据并显示
- Android中的Activity或Dialog并不能直接向FrameBuffer中写入数据,而是需要先写入到GraphicBuffer(图形缓冲区),然后进入到BufferQueue中
- BufferQueue采用了生产者-消费者的模型,其中生产者为BufferQueueProducer,通过调用dequeueBuffer()获取一个空闲的缓冲区,并填入要绘制的图形数据,接着调用queueBuffer()将Buffer重新返回给BufferQueue
- BufferQueue中的消费者为BufferQueueConsumer,通过调用acquireBuffer()从BufferQueue中拿到一个被填满的缓冲区并消费
图解
这是App进程与SurfaceFlinger进程的关系
这是App进程,WMS与SurfaceFlinger的关系
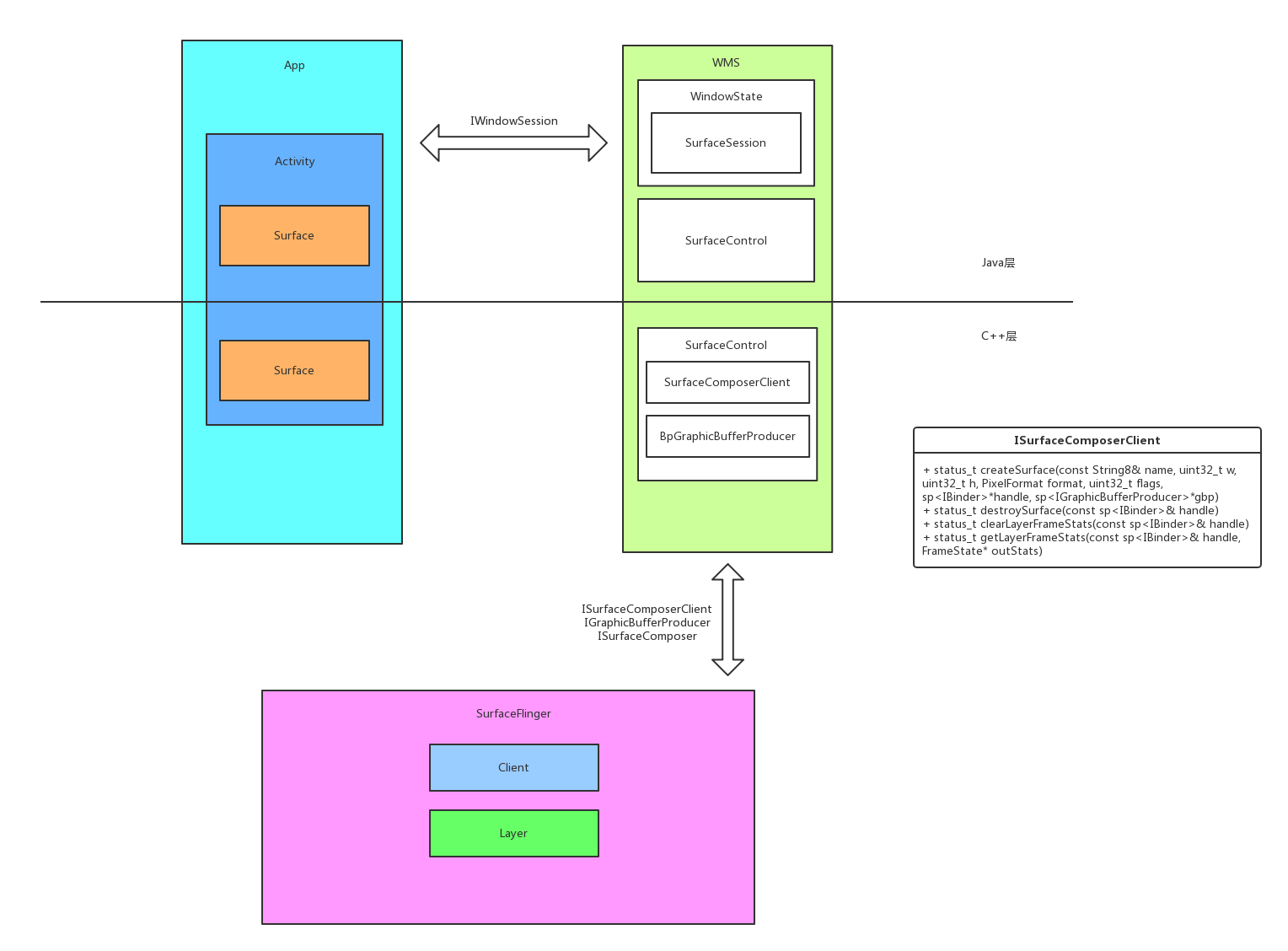
WMS负责控制所有App进程中窗口的显示,只有经过AMS与WMS的控制,在适当的时机,App才有向SurfaceFlinger中写入数据的机会。
图形缓冲区采用的是生产者-消费者模式:
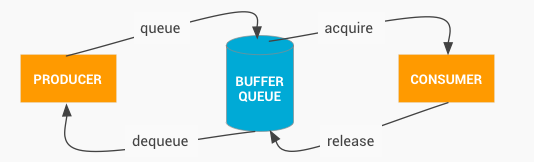
流程如下:
1)App端与WMS建立连接,WMS与SurfaceFlinger建立连接,在这个过程中会创建大量的对象,为绘图做好准备
2)App端请求SurfaceFlinger进程的BufferQueue分配图形缓冲区;
3)BufferQueue通过Gralloc在匿名共享内存分配到空间,并将文件描述符fd通过GraphicBuffer传给App进程;
4)App进程通过fd将缓冲区映射到自己的内存空间中,并将首地址传递给图形库;
5)图形库从首地址开始绘制;
6)App端绘制完成后将缓冲区交还给BufferQueue;
7)queueBuffer()时,Layer通知SurfaceFlinger刷新
显示前的准备工作
从Activity到ViewRootImpl
一个Activity创建好之后,它的显示过程是从ActivityThread中handleResumeActivity()开始的,该方法的主要代码如下:
|
|
这个方法比较简单,主要就是分两种情况:第一种是当前Activity的Window还未添加到WindowManager,那么就需要调用wm.addView(decor,l);将窗体添加到WindowManager进行管理。当然,如果在resume的过程中我们启动了另外一个Activity,那么当前Activity会暂时隐藏。
第二种情况则是窗体已经添加到WM中,那么此时其实就是重新显示出来即可,这个过程中还会涉及到configuration的改变等。
由于这里我们关注一个Activity被创建后是如何显示出来的,所以这里关注第一种情况即可。
该方法中wm其实是WindowManagerImpl对象,故进入WindowManagerImpl.addView()中分析:
|
|
这个方法很简单,就是调用了WindowManagerGlobal的addView()方法:
|
|
注意到在这个方法中创建了ViewRootImpl对象,并且在最后调用它的setView()方法:
|
|
注意其中的mWindowSession.addToDisplay()这个调用,这里通过Binder通信,最终进入Session.addToDisplay()方法:
|
|
显然,它只是调用WindowManagerService的addWindow()方法:
|
|
注意到在这里创建了WindowState对象,并且调用其attach()方法:
|
|
非常简单,就是调用Session的windowAddedLocked()方法:
|
|
注意在这里创建了SurfaceSession对象,这个构造方法如下:
|
|
这个注释说得很清楚,就是建立与SurfaceFlinger的连接,那究竟是如何建立连接的呢?继续往下看便知。
nativeCreate()是个jni调用,其定义在android_view_SurfaceSession.cpp文件中:,
|
|
显然,这里创建了SurfaceComposerClient对象,其构造方法如下:
|
|
其初始化列表中对Compoer对象mComposer进行了赋值。
但是还是没看到建立连接的地方呀?难道注释写错了?
SurfaceComposerClient
注意看SurfaceComposerClient的定义:
|
|
它是继承自RefBase的,从而在它首次被强引用的时候,就调用onFirstRef()方法:
|
|
在这里,通过调用ComposerService::getComposerService()获取到ISurfaceComposer对象:
|
|
显然,会在ComposerSerivce::connectLocked()方法中建立连接,并且给mComposerService赋值。
|
|
注意其中的getService()方法是来自IServiceManager.cpp中,其目的是根据服务名称(“SurfaceFlinger”)找到对应的服务并且返回其在C++层的代理,这是属于Binder通信的内容,不熟悉的小伙伴可以自己查看相应的内容。
经过getService(name,&mComposerService)之后,mComposerSerivce就持有了SurfaceFlinger在system_server进程中的代理,其实此时mComposerService是一个BpSurfaceComposer对象(ps.从这里可以看出这个mComposerService的命名其实相当不规范,应该取名叫mBpSurfaceComposer才恰当)。
再回到SurfaceComposerClient::onFirstRef()中,可知此时sm->createConnection()其实就是调用BpSurfaceComposer::createConnection()方法:
|
|
这是典型的C++层Binder通信,最终会调用到SurfaceFlinger::createConnection()方法:
|
|
在这里创建了一个Client对象并赋值给client,Client是SurfaceFlinger的一个帮手。
再回到SurfaceComposerClient::onFirstRef()方法中,可知conn其实就是一个SurfaceFlinger中Client对象在WMS中的一个代理,即BpSurfaceComposerClient对象(相对地,Client继承自BnSurfaceComposerClient)。mark这个,在后面会用到它。
绘图过程
虽然前面已经创建了很多对象,但是实际上还没有完全做好准备,有些对象是直到真正开始绘制时才创建。首先从SurfaceControl开始。
SurfaceControl
有很多种情况可以触发重绘,一个典型的过程是Choreographer.doFrame()—>Choreographer.doCallbacks()—>TraversalRunnable.run()—>ViewRootImpl.doTraversal()—>ViewRootImpl.performTraversals()—>ViewRootImpl.relayoutWindow(),这个方法非常重要,因为在这里面会创建SurfaceControl对象:
|
|
在这个方法中进行了Binder调用,最终会调用Session.relayout()方法:
|
|
显然,这里就是直接调用WMS的relayoutWindow()方法:
|
|
在这里通过调用WindowStateAnimator的createSurfaceLocked()方法创建SurfaceControl对象:
|
|
显然,在这里调用SurfaceControl的构造方法创建了一个SurfaceControl对象,并且开启事务模式进行相关属性的设置。SurfaceControl的构造方法中做了很多的事情:
|
|
跟上面类似,这里也有一个nativeCreate()的jni调用:
|
|
其中android_view_SurfaceSession_getClient()方法如下:
|
|
显然,这里是将jobject这个句柄重新转换为SurfaceComposerClient指针,而这个指针指向的就是前面创建的SurfaceComposerClient对象。
再回到nativeCreate()方法中,显然它是调用SurfaceComposerClient::createSurface()方法创建一个C++层的SurfaceControl对象:
|
|
这里的重点其实不在新建SurfaceControl对象,而在于创建这个对象之前的准备工作,其中mClient在前面说过,它其实是一个BpSurfaceComposerClient对象,所以mClient->createSurface()最终会调用到SurfaceFlinger进程中Client对象的createSurface()方法:
|
|
注意这里调用了SurfaceFlinger的postMessageSync()方法,通知它去进行处理,最终会调用到MessageCreateLayer的handler()方法,从而调用SurfaceFlinger::createLayer()方法:
|
|
这里会走到第一个分支,即调用createNormalLayer()方法:
|
|
在这里新建了Layer对象,以及给gbp赋值,其中gbp是IGraphicBufferProducer类型指针,而Layer::getProducer()方法很简单:
|
|
而这个类的创建在onFirstRef()中:
|
|
在这个方法中,通过调用BufferQueue::createBufferQueue()创建了IGraphicBufferProducer对象和IGraphicBufferConsumer对象,它们分别是图形缓存的生产者和消费者。
下面就详细分析一下createBufferQueue()这个方法,注意最后一个参数allocator的默认值为NULL:
|
|
可见,这个方法其实就做了三件事:
- 创建了一个BufferQueueCore对象
- 借助刚刚创建的BufferQueueCore对象,创建一个BufferQueueProduer对象
- 类似地,创建一个BufferQueueConsumer对象
BpSurfaceComposerClient::createSurface()方法
再回到SurfaceComposerClient::createSurface()方法中,前面已经分析了mClient->createSurface()的跨进程调用过程,但是没有讲在跨进程之前,在WMS中是如何调用的。
由于mClient其实只是surface-flinger进程中Client对象在WMS中的代理,即BpSurfaceComposerClient对象,所以mClient->createSurface()首先是执行BpSurfaceComposerClient::createSurface()方法:
|
|
可见gbp成了surface-flinger进程中BufferQueueProducer在WMS中的一个代理,即BpGraphicBufferProducer对象,后面可通过gdp进行跨进程调用到suface-flinger进程中的BufferQueueProducer对象。
C++层Surface对象的创建
再回到WMS.relayoutWindow()方法,在执行完SurfaceControl surfaceControl=winAnimator.createSurfaceLocked();之后会执行outSurface.copyFrom(surfaceControl);方法:
|
|
这个方法的作用是让当前Surface指向另一个Surface所持有的数据,这里有jni调用:
|
|
这个方法很简单,就是先将Java层的句柄转换为C++层的SurfaceControl对象(之前创建的SurfaceControl对象是以long型保存在Java层的SurfaceControl对象中),之后调用SurfaceControl::getSurface()方法获得C++层的Surface对象,并且将句柄保存在Java层的Surface对象中。其中getSurface()方法如下:
|
|
显然,这里如果mSurfaceData为空的话,则会创建Surface对象。至此,C++层的Surface对象就创建好了。
准备工作总结
到这里为止,可以总结一下准备工作了,主要流程如下:
- 从ActivityThread中handleResumeActivity()开始,调用到ViewRootImpl.setView()方法,最终通过Binder通信调用到WMS.addWindow()方法,从而在WMS中创建SurfaceSession对象,而这个Java层的SurfaceSession对象其实只是C++层SurfaceComposerClient对象的一个封装
- 在创建SurfaceComposerClient对象的过程中,还建立了WMS与SurfaceFlinger的连接,并且在SurfaceFlinger进程中创建了Client对象, Client与SurfaceComposerClient是Binder通信的对端,它们分别在system_server和surface_flinger进程中
- 接收到绘制信号后,触发重绘流程,即horeographer.doFrame()—>Choreographer.doCallbacks()—>TraversalRunnable.run()—>ViewRootImpl.doTraversal()—>ViewRootImpl.performTraversals()—>ViewRootImpl.relayoutWindow()
- ViewRootImpl.relayoutWindow()中,最终会通过Binder通信调用到WMS的relayoutWindow()方法,在该方法中创建了Java层的SurfaceControl对象
- 在创建Java层的SurfaceControl对象过程中,会通过jni调用在C++层创建一个SurfaceControl对象,并且通过Binder通信让Client对象创建一个Layer对象
- 在WMS.relayoutWindow()方法中,创建好SurfaceControl对象之后,会调用outSurface.copyFrom(surfaceControl);创建Surface对象,并且将句柄保存在Java层的SurfaceControl对象中
开始进入绘制流程
做完了上面这些准备,建立了App与WMS的连接,以及WMS与SurfaceFlinger的连接,并且准备好了Surface对象,下面就可以开始绘图了。前面说过,触发重绘最终会走到ViewRootImpl.draw()方法中,该方法如下:
|
|
显然,在绘制时有两种情况,即采用硬件加速或不采用,采用硬件加速进行绘制会在后面专门分析,这里先考虑drawSoftware()这种情况,该方法的主要代码如下:
|
|
mSurface在ViewRootImpl的构造方法之前就通过final Surface mSurface=new Surface();的定义创建了
这里有三个流程很重要,分别是canvas = mSurface.lockCanvas(dirty); mView.draw(canvas);以及surface.unlockCanvasAndPost(canvas);其中mView.draw(canvas);就是真正地调用skia图形库进行绘制的过程,这个在前一篇文章中分析过,这里先不分析。
Surface.lockCanvas()方法分析
下面先分析canvas=mSurface.lockCanvas(dirty);这个调用
|
|
这个方法是用于提供一个Canvas,从而让图形数据可以写入到Surface中,当然,最终其实是写入到surface-flinger进程中的Layer中。在调用这个方法之后需要调用unlockCanvasAndPost()以将要绘制的内容提交给Surface,所以这两个方法需要成对出现。
nativeLockCanvas()方法如下:
|
|
这个方法的主要作用如下:
- 将之前创建的C++层的Surface对象的句柄还原为Surface指针
- 根据Java层传递的数据获取脏区域的left,top,right,bottom这四个角点的数值,从而得到矩形的大小和位置
- 调用Surface的lock()方法,将申请的图形缓冲区赋值给outBuffer,这个lock()方法涉及到的东西非常多,后面将会详细分析
- 通过bitmap.setPixels(outBuffer.bits)将ANativeWindow_Buffer中的bits传递给SkBitmap对象,其中bits即为图形缓冲区的首地址。SkCanvas之后就可以通过这个首地址来输出UI数据了
- 创建一个Skbitmap对象,并且填充它的图形缓冲区,最终赋值给Java层的Canvas对象
- 将剪裁位置大小信息赋值给java层的inOutDirty这个Rect对象
至此,drawSoftware()方法中canvas = mSurface.lockCanvas(dirty);这个调用就分析完了。为了搞清楚ANativeWindow_Buffer的来源,下面开始分析Surface的lock方法。
C++层的Surface::lock()方法
Surface::lock()方法如下:
|
|
这个方法的主要工作为:
- 调用dequeueBuffer()函数获取图形缓冲区
- 计算需要绘制的dirty区域,旧的区域则只需copy数据即可
其实注释都已经写得很清楚了,就是将需要更新的dirty区域剪裁出来,剩余不需要更新的区域则不用重绘。在大部分情况下,UI只有一小部分发生变化(如点击按钮时,按钮颜色发生变化),这一小部分UI只对应整个GraphicBuffer中的一小块存储(即代码中的dirtyRegion),如果此时所有区域都更新,则会造成很大的资源浪费。
此时就需要将变化的图像和没有发生变化的图像进行叠加,上一次绘制的信息保存在mPostedBuffer中,而这个mPostedBuffer则要在unLockAndPost函数中设置。这里将根据需要,将mPostedBuffer中的旧数据copy到BackBuffer中。后续的绘画只需要更新脏区即可。
- lock和unlock分别用来锁定和解锁一个指定的图形缓冲区,在访问一块图形缓冲区的时候,例如,向一块缓冲区写入内容的时候,需要将该图形缓冲区锁定,用来避免访问冲突,锁定之后,就可以确定缓冲区的起始地址,并保存在vaddr中。在访问完一场图形缓冲区之后,需要解锁它。
图形缓冲区的分配
Surface的dequeueBuffer()方法如下:
|
|
显然,这个方法是通过调用IGraphicBufferProducer对象(其实是BpGraphicBufferProducer对象,在前面分析过)的dequeueBuffer()方法来获得图形缓冲区,如果没有找到空闲的缓冲区,就需要调用mGraphicBufferProducer->requestBuffer(buf,&gbuf);从匿名共享内存中重新分配。
显然,这里会通过跨进程调用到BufferQueueProducer::dequeueBuffer()方法:
|
|
这个方法虽然看起来很长,但是其实很简单,就是根据指定的index取出mSlots中的slot中的buffer,然后让buf指向它。
Surface.unlockCanvasAndPost()方法分析
Surface.unlockCanvasAndPost()方法如下:
|
|
由于我们这里只分析非硬件加速的情况,所以执行unlockSwCanvasAndPost()方法:
|
|
没啥好说的,就是jni调用:
|
|
这个方法的主要作用为:
- 获取java层保存的Surface句柄,还原为Surface指针
- 解除java层对native层的SkBitmap对象的引用