1.起因
今天在做流量分析时,从服务端记录的请求日志发现流量排名前10的用户里有一个用户的某个网络请求竟然在很短的时间内请求了10000多次! 那段时间内的流量占比如下图:
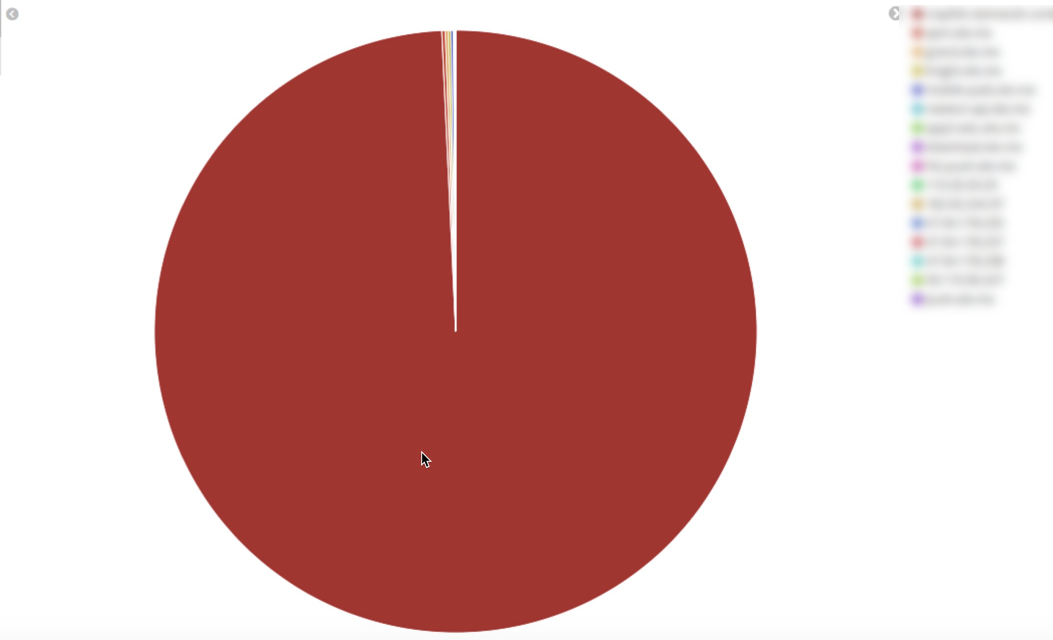
2.分析
考虑到客户端采用AOP的方式记录了所有的网络请求信息,于是赶紧把客户端日志拉上来进行分析,看看是不是某些条件触发的,却意外地并没有看到频繁地网络请求! 我的内心是崩溃的!!!
既然客户端日志查不出什么问题,于是只能继续从服务端日志入手,仔细看一下简直吓尿了,那一万多个请求竟然都是同一个requestId,于是怀疑是服务端的日志记录有问题,但是可以看到各个请求虽然requestId一样,但是时间戳是不一样的,那就排除了服务端的日志记录出错的可能!
那就只能是客户端的网络请求的重试机制有问题了!!!
但是OkHttp的重试机制很简单啊,就是添加拦截器,示例代码如下:
|
|
而且由于并不是一个很紧迫的配置项,所以当时并没有给它添加重试的拦截器。
那就只可能是它自身的重试机制出问题了,由于我们App里面用的是3.4.2,其对应的重试代码如下:
|
|
这段代码是在RetryAndFollowUpInterceptor中的intercept()方法中,这个类的目的很明确,就是用于重试和跳转,但是redirect最大次数是20, 那怎么会无限重试呢?
显然只可能是在if (++followUpCount > MAX_FOLLOW_UPS) 这个条件判断之前,继续分析下去会发现在出现RouteException或者IOException时,会调用recover()方法,而如果每次recover()都返回true的话,就不会释放连接,而是一直重试下去。
那有没有可能我们这个请求是发生了RouteException或者IOException呢?
看到服务端有如下记录:
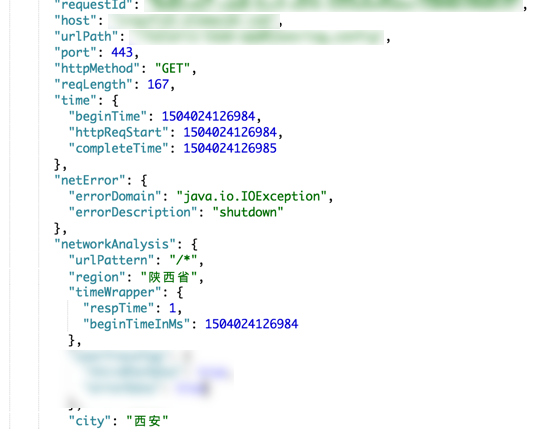
注意其中的errorDomain和errorDescription,很清楚地可以看到是发生了shutdown的IOException,其实这种情况一般发生在服务器处于较大压力的情况下,再看一下recover()这个方法:
|
|
由于应用层并没有禁止重试,Request的body()也并非UnrepeatableRequestBody,而且路由选择也不为false, 所以最终返回true,从而判定为连接可以恢复,最终导致无限重连,耗费大量的流量。
之后在看okhttp的issues时发现其实这个bug早在2016.7.28(对应版本为3.4.1)就有了提了,如下图所示:
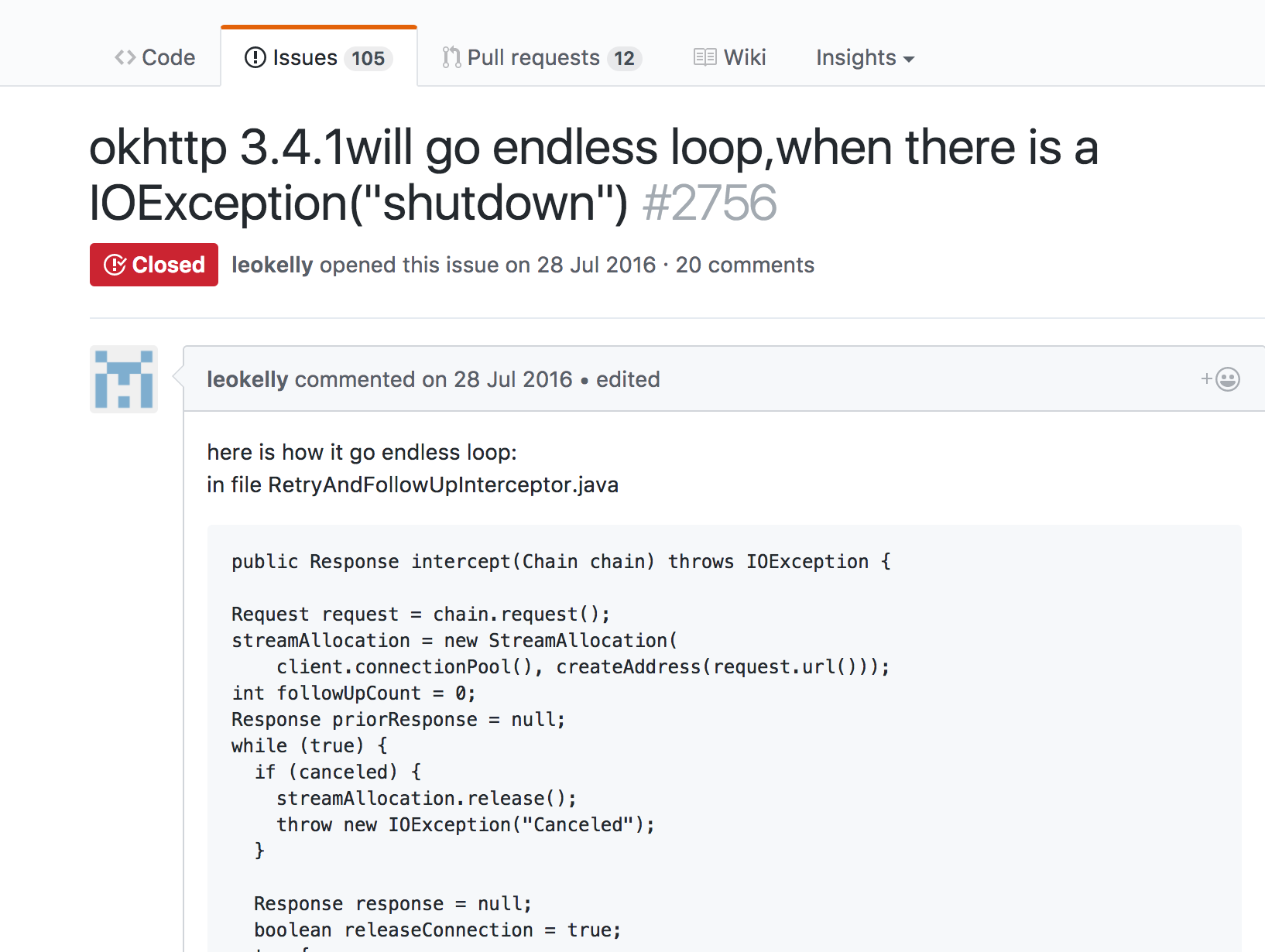
只是这个bug的修复在3.4.2并没有完成,而是一直到3.5.0才完成,详细信息见链接Gracefully recover from an HTTP/2 connection shutdown at start of request. #2992 所以如果遇到类似问题的同学,请将okhttp升级到3.5.0以上。
3.Root Cause
不管是从okhttp的issue还是我们自己的日志记录来看,这种情况的出现都是非常小概率的,那到底是什么情况下会出现shutdown这样的IOException呢?
采用charles抓包,发现该网络请求采用的竟然是http 2.0协议,如下图所示:
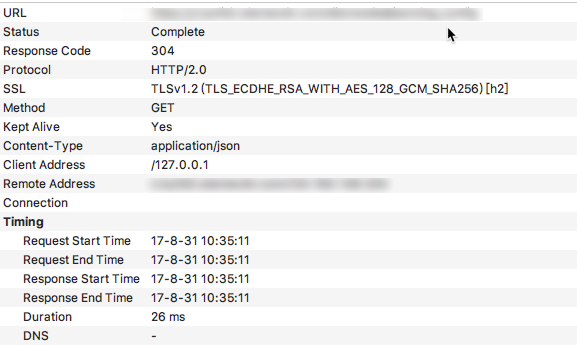
为了更好地理解h2的请求过程,简单地了解一下h2与1.1请求的区别。
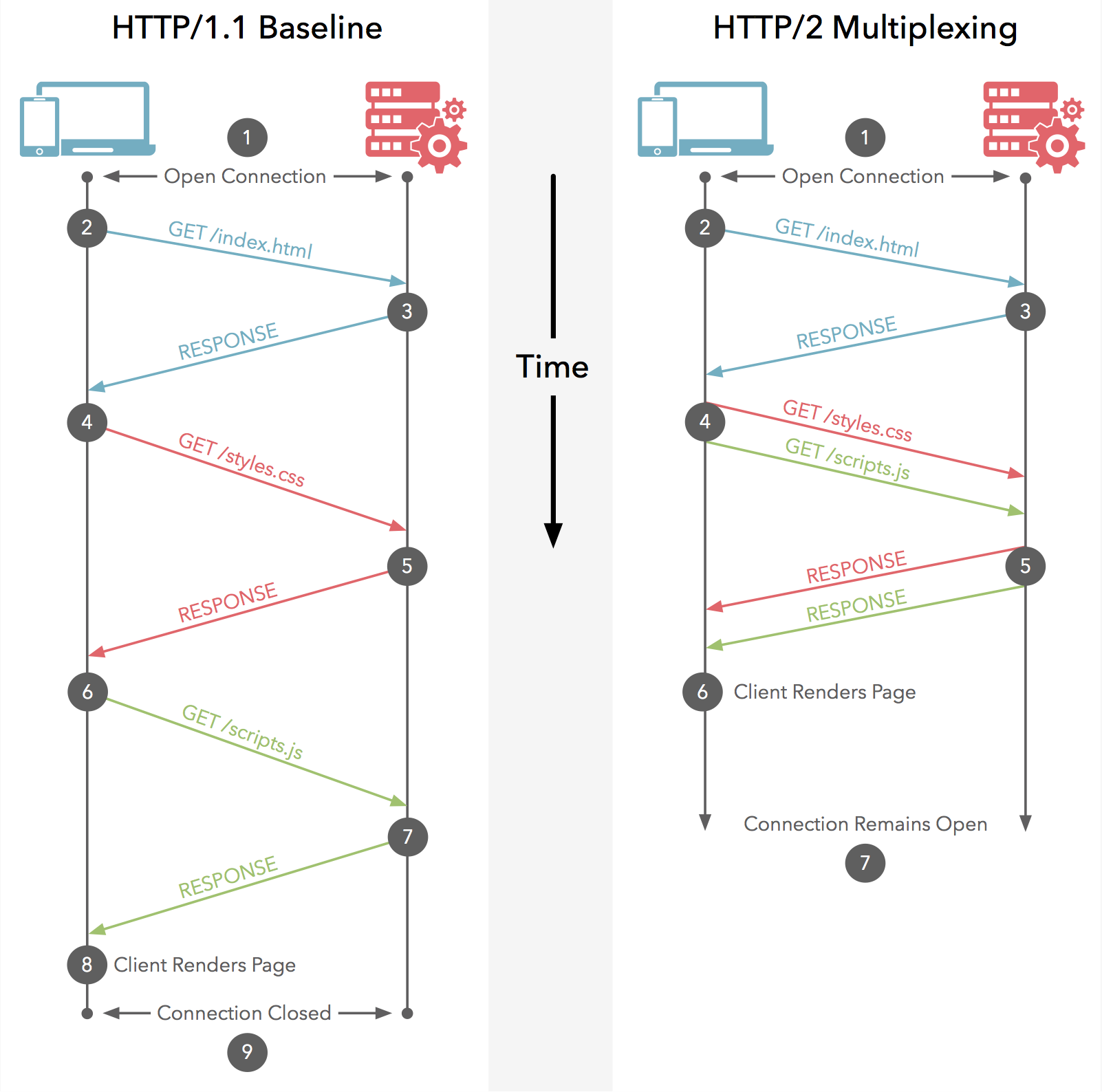
h2是基于Google的SPDY协议的,其实h2和1.1最大的区别就是多路复用,即1.1中必须一个连接对应一个stream,而h2中可以多个stream共用一个连接,如下图所示:
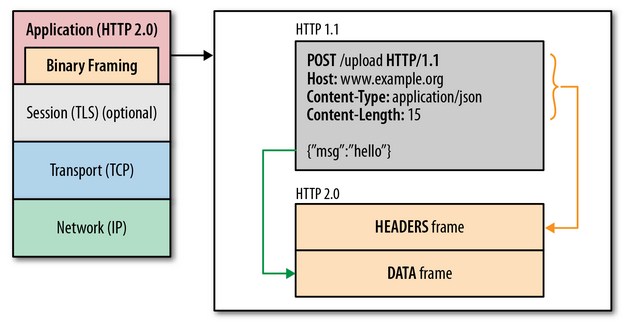
其实现的方式就是将要传输的信息分割成一个个二进制帧,其中首部信息会放到HEADER Frame中,而request body会放到DATA Frame中,示意图如下:
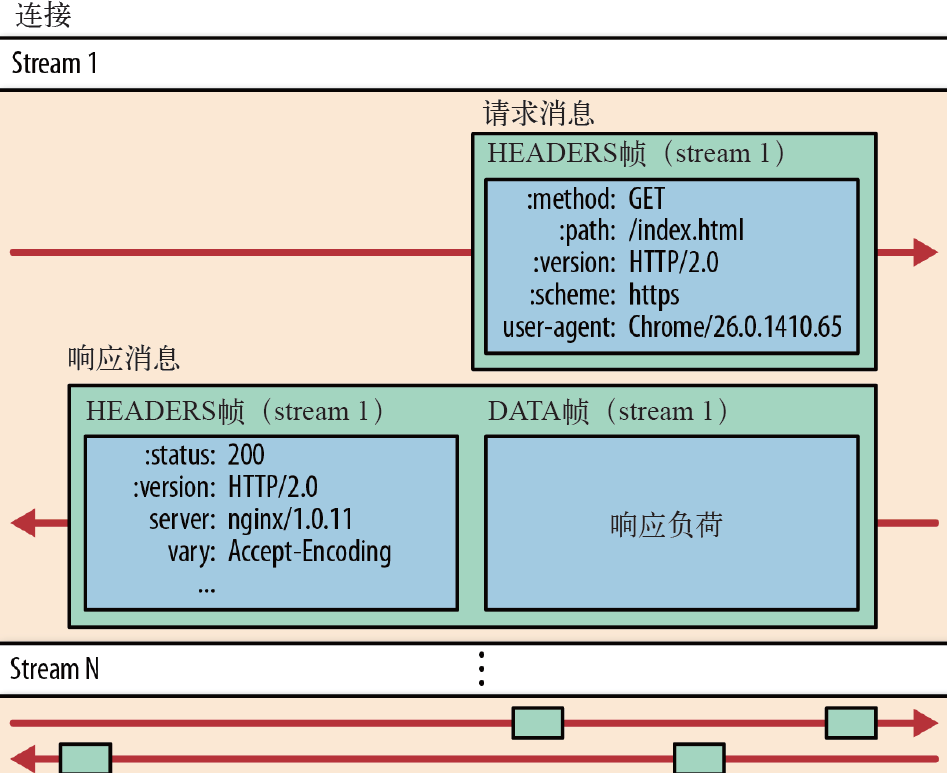
帧传输的示意图如下:
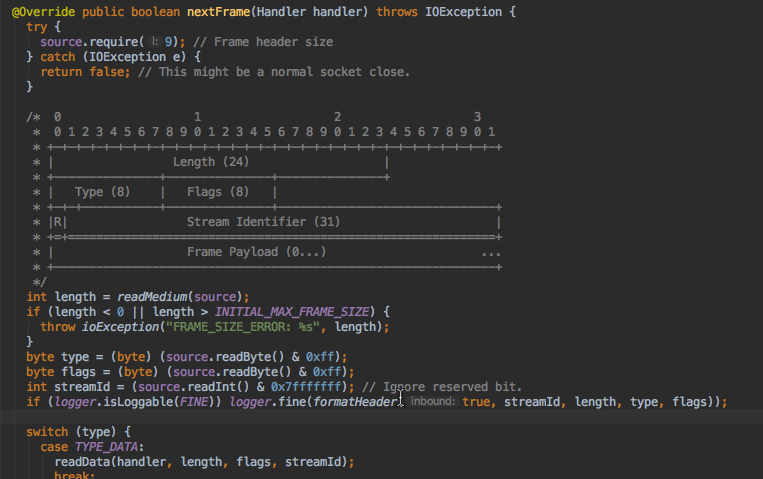
而数据帧的格式其实在okhttp的注释中就有,如下:
由于TCP协议的滑动窗口,因而1.1中每次建立连接后都是需要慢启动,即数据先是慢慢地传,之后滑动窗口变大,才能高速传递,而h2由于共用连接,不仅提高于吞吐量,而且可以使平均传输速度增大,如下的动图很好地表示了h2与1.1在传输相同图片时的对比:
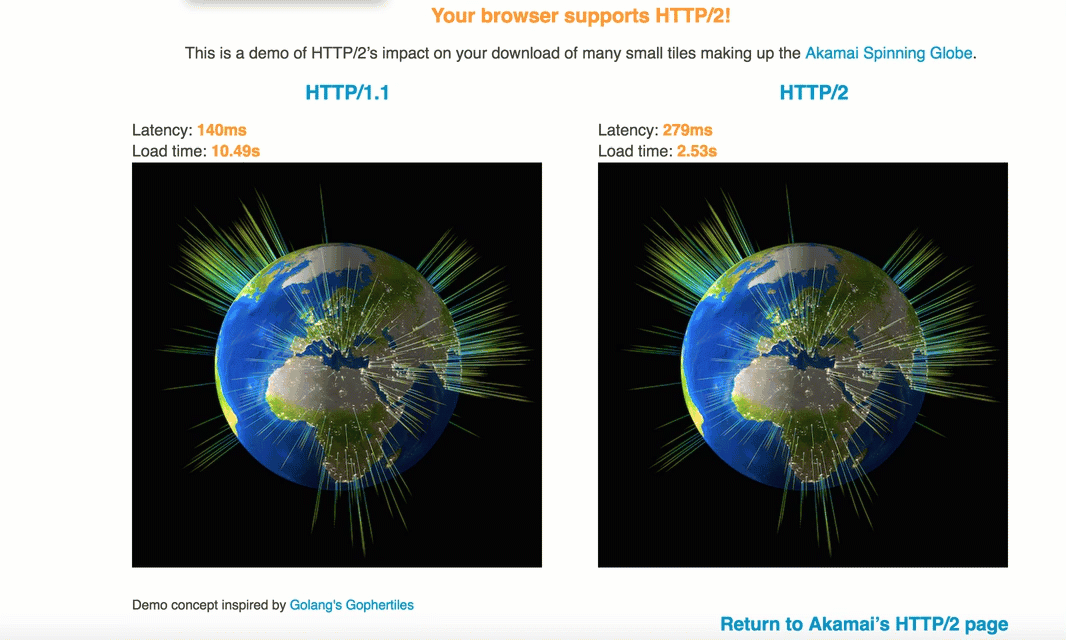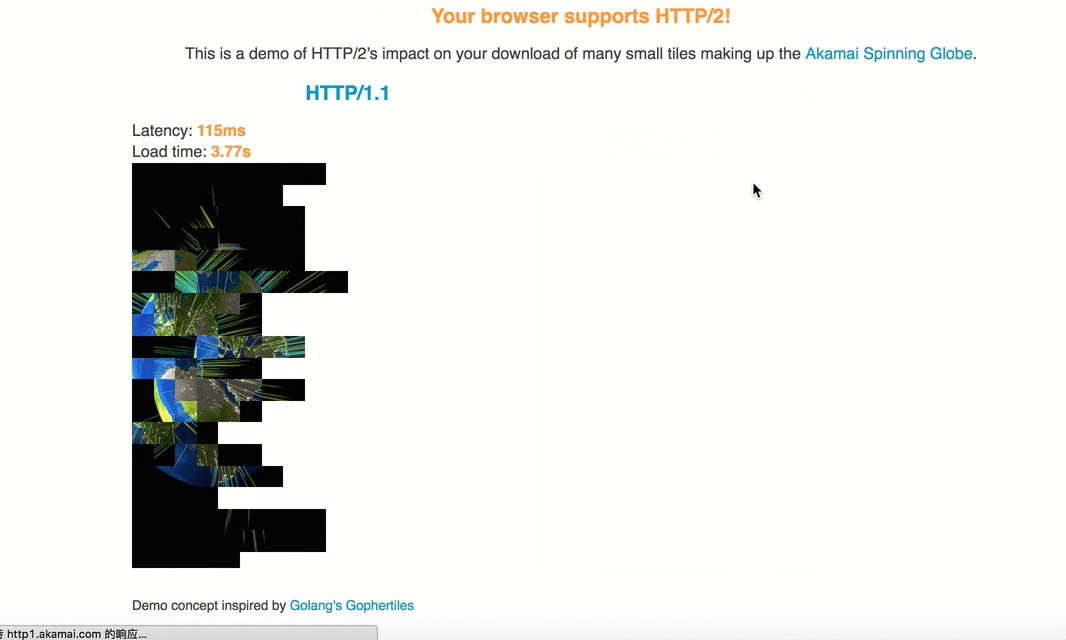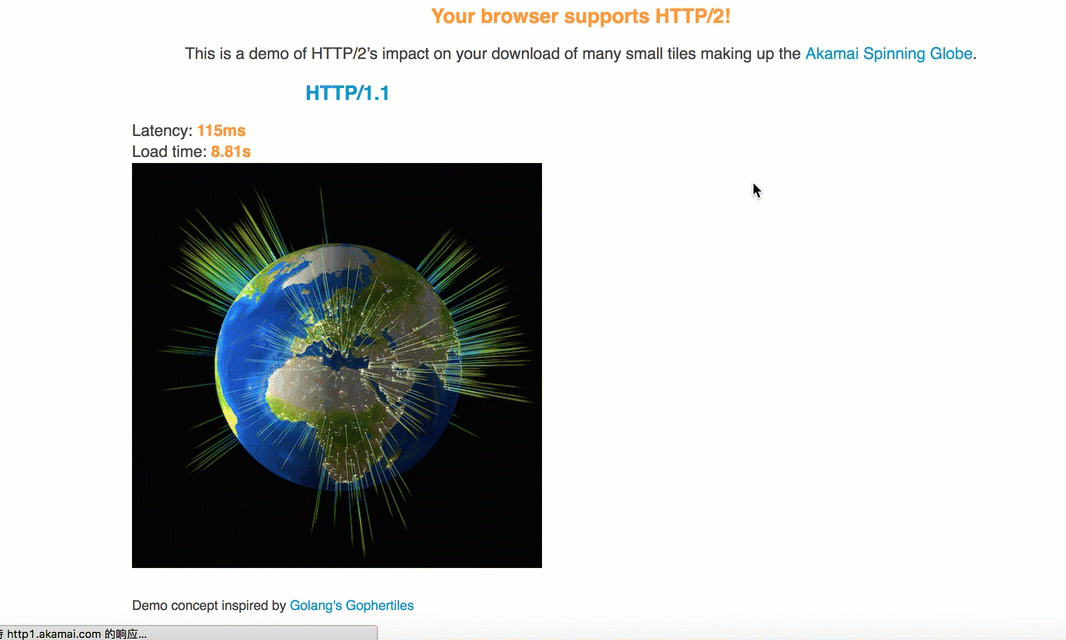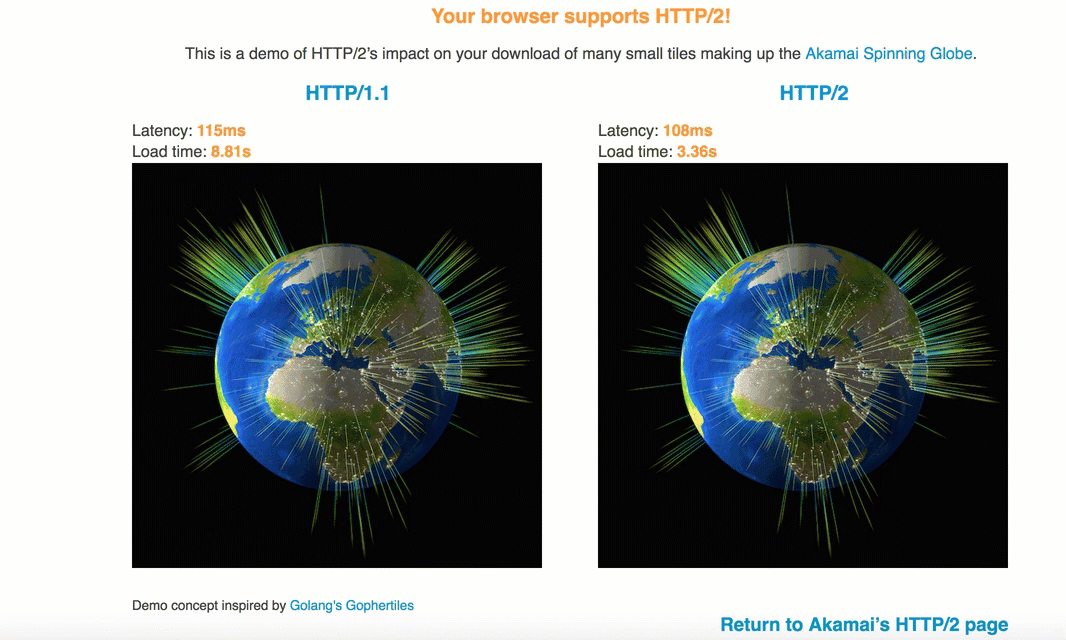
另外,由于h2进行了首部压缩,所以其实它还可以节省流量。
了解了这些,知道h2是通过帧传输的,就能很快地梳理出h2协议的请求过程,如下图所示:
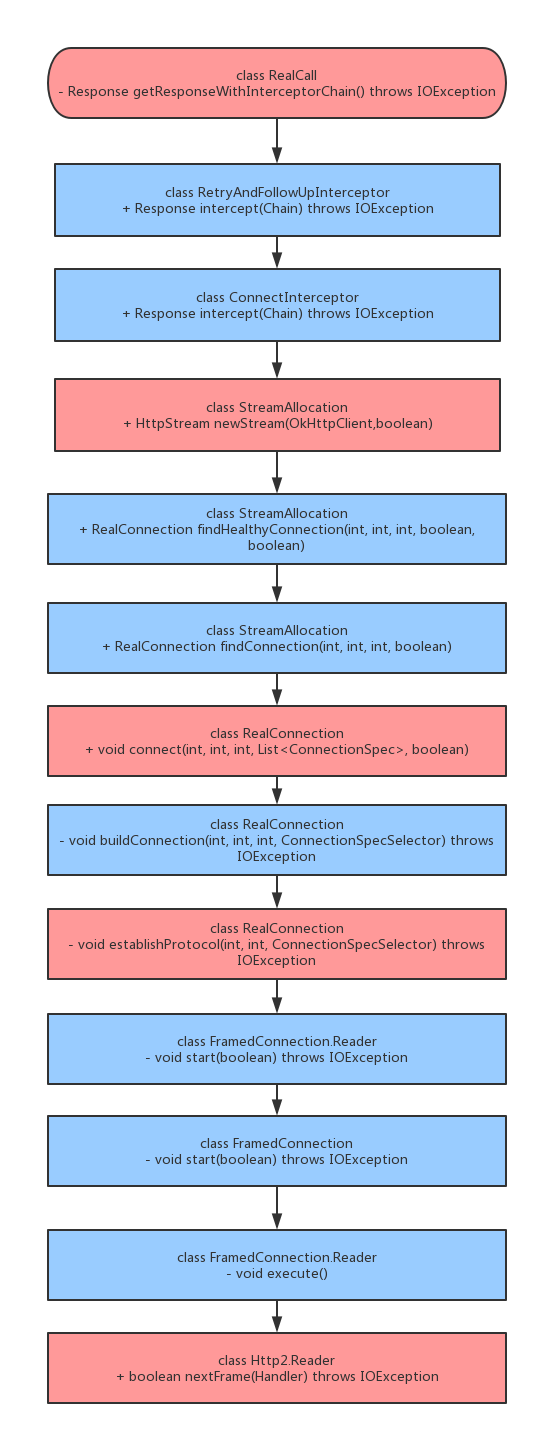
其中重要的节点我都用红色标出来了,如前面所说,h2协议是一帧一帧地读取地,所以正常的请求下Http2.Reader.nextFrame()方法中的type是TYPE_HEADERS和TYPE_DATA,该方法如下:
|
|
一直到服务端出现某种错误关闭连接,okhttp就会从数据帧中读取到TYPE_GOAWAY的标志位,然后进入readGoAway()的流程中,该方法如下:
|
|
注意到这个方法中的handler其实是实现了Handler接口的FramedConnection.Reader,其goAway()方法如下:
|
|
注意其中将shutdown设置为true了,之后,当StreamAllocation再次调用nextFrame()时,就会抛出名为”shutdown”的IOException, 主要代码如下:
|
|
由于中间没有捕获IOException的操作,所以这个异常就会一直往上传递到RetryAndFollowUpInterceptor的intercept()方法中,最终导致前面所说的死循环。
而至于服务端为何会在某些请求中shutdown, 查看流量统计就可以发现这个接口在一天时间内有高达几亿次请求,远远超过了当初设计的要求,而导致这个的原因是客户端用户的快速增长以及轮询请求太过频繁,从而使服务端不得不关闭一些连接以防止宕机。
4.为何客户端日志没有记录到重试的请求
这个其实就涉及到okhttp的执行流程了,这里有很多的博客理解有很大的错误,其实各个Interceptor并不是顺序执行的,而是递归执行的,有些Interceptor甚至会执行多次。
而客户端进行AOP时选择的切面是RealCall中的getResponseWithInterceptorChain()方法中,而重试发生在内部的RetryAndFollowUpInterceptor中,所以无法得知。
5.扩展问题
那如果这里不采用AOP,而是采用为okhttpclient增加Interceptor的方法,能够记录下重试的请求吗?
注意以下代码:
|
|
显然,为client增加的Interceptor(确切地说是应用拦截器)在最外层,那它对于RetryAndFollowUpInterceptor的内部执行过程就一无所知了,所以即使采用为okhttpclient增加Interceptor的方法,也无法记录下重试的过程。
但是如果为client增加networkInterceptors(这些被称为网络拦截器),由于在最内层,所以是可以记录到包括重试在内的所有网络请求的。
而如果要想采用AOP的方式记录下重试的过程的话,还是只能对RetryAndFollowUpInterceptor内层的Interceptor进行切面,比如ConnectInterceptor或者CallServerInterceptor.